Collection接口
集合
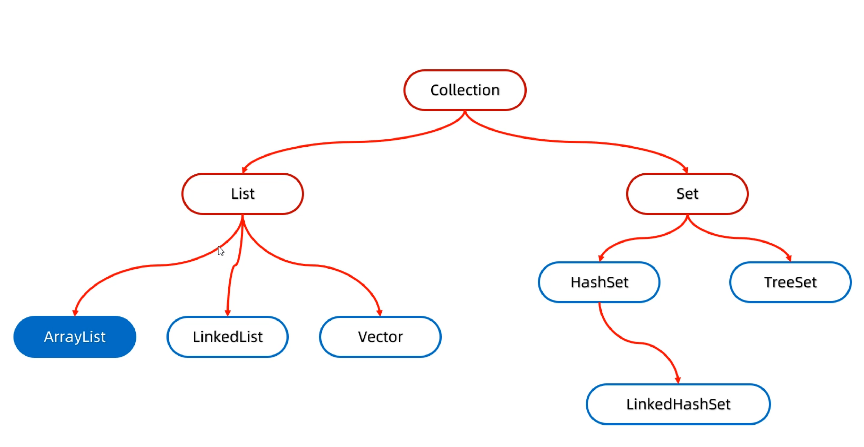
集合中可以分为单列集合和多列集合
单列集合(collection)
每次只能往集合里面添加一个元素
多列集合(map)
添加数据的时候,一次添加一对数据
Collection(接口)
Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的
| 方法名称 | 说明 |
|---|---|
| public boolean add(E e) | 把给定的对象添加到当前集合中 |
| public void clear() | 清空集合中所有的元素 |
| public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| public boolean contains(Object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty() | 判断当前集合是否为空 |
| public int size() | 返回集合中元素的个数/集合的长度 |
注意:在contains方法中,底层是依赖equals方法进行判断是否存在,所以,如果集合中存储的是自定义对象,也想通过contains方法来判断是否包含,那么在javaBean类中一定要从写equals方法。

Collection的遍历方式
迭代器遍历
迭代器在Java中的类是Iterator,迭代器是集合专用的遍历方式,是不依赖索引就可以遍历的,如果在遍历过程中需要删除元素,请使用迭代器,如果仅仅想遍历,使用增强for或者Lambda表达式
Collection集合获取迭代器
| 方法名称 | 说明 |
|---|---|
| Iterator | 返回迭代器对象,默认指向当前集合的0索引 |
Iterator中常用的方法
| 方法名称 | 说明 |
|---|---|
| boolean hasNext() | 判断当前位置是否有元素,有元素返回true,没有元素返回false |
| E next() | 获取当前位置的元素,并将迭代器对象移向下一个位置 |
1 | |
细节注意点
- 报错NoSuchElementException(没有这个元素异常)
- 迭代器遍历完毕,指针不会复位。如果需要再次遍历,可以再次获取迭代器对象(Iterator)
- 循环中只能使用一次next方法
- 迭代器遍历时,不能用集合的方法进行增加或者删除
迭代器源码分析

增强for遍历
增强for的底层就是迭代器,为了简化迭代器的代码书写的
所有的单列集合和数组才能用增强for进行遍历
1 | |
增强for的细节
- 修改增强for中的变量,不会改变集合中原本的数据
Lambda表达式遍历
| 方法名称 | 说明 |
|---|---|
| default void forEach(Consumer<? super T> action) | 结合Lambda遍历集合 |
forEach底层原理
其实也会自己遍历集合,依次得到每一个元素,把得到的每一个元素,传递给下面的accept方法
1 | |
List(接口)
List系列集合:添加的元素是有序(指的是存取顺序)、可重复(集合中元素是可以重复的)、有索引(可以通过索引获取集合的每一个元素)
- Collection的方法List都继承了
- List集合因为有索引,所以多了很多索引的操作方法
| 方法名称 | 说明 |
|---|---|
| void add(int index,E element) | 在此集合中指定位置插入指定元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
细节
add方法,在指定位置插入元素后,原来索引上的元素会依次往后移
remove方法,在Collection中remove方法传递的是一个Object对象,如果List的参数是Integer类型,在remove(1);的时候,删除的是1索引上的元素还是1这个元素?
删除的是1索引上的这个元素,因为在调用方法的时候,如果方法出现了重载现象,优先调用,实参和形参类型一致的那个方法。
remove方法在删除指定索引处的元素后,原来索引后面的元素会依次往前移
list遍历
- 迭代器(在遍历的过程中需要删除元素,请使用迭代器)
- 列表迭代器(在遍历的过程中需要添加元素,请使用列表迭代器)
- 增强for(仅仅想遍历)
- Lambda表达式(仅仅想遍历)
- 普通for循环
1 | |
ArrayList
ArrayList可以直接使用List和Collection中的方法
底层原理
利用空参创建的集合,在底层创建一个默认长度为0的数组,数组的名字叫elementData,还会存在一个变量size,默认值为0,size有两层含义,分别表示元素个数和下次存入的位置。
添加第一个元素时,底层会创建一个新的长度为10的数组,数组的默认值为null,在长度为10的数组中添加元素后,size++。
存满时,会自动扩容原来数组长度的1.5倍
如果一次添加多个元素,数组扩容1.5倍还放不下(15个),则新创建数组的长度以实际为准(如果添加100个数据,则长度为110=100+10)

添加多个元素,或者是数组中元素满了之后在添加一个元素

LinkedList
- 底层数据结构式双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的
- LinkedList本身多了很多直接操作首尾元素的特有API
| 特有方法 | 说明 |
|---|---|
| public void addFirst(E e) | 在该列表开头插入指定的元素 |
| public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素 |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |

Vector(jdk1.2就被遗弃)
Set(接口)
Set接口中的方法基本上与Collection的API一致。
Set系列集合:添加的元素是无序(存取无序)、不重复(集合中不能存储重复的元素)、无索引(不能通过索引去获取元素,所以不能使用普通for去循环遍历)
HashSet(无序、不重复、无索引)
- HashSet集合底层采取哈希表存储数据
- 哈希表是一种对于增删改查数据性能都比较好的结构
哈希表的组成
- JDK8之前:数组+链表
- JDK8开始:数组+链表+红黑树
哈希值(对象的整数表现形式)
添加数据的时候,添加数据的数组下标 int index = (数组长度-1)&哈希值;
为了方便计算,则需要把对象转换为一个整数才能计算。
- 根据hashCode方法算出来的int类型的整数
- 该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
- 一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值。
对象的哈希值特点
- 如果没有重写hashCode方法,就是通过地址值去计算,所以不同对象计算出的哈希值是不同的
- 如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
1 | |
HashSet底层原理
HashSet
创建一个默认长度16,默认加载因子为0.75(用于数组的扩容,当数组存入个数到16*0.75就开始扩容)的数组,数组名table,数组中数据都为null
添加数据时,根据元素的哈希值跟数组的长度计算出应存入的位置(计算公式:int index = (数组长度-1)& 哈希值)
计算出存入的位置后,判断当前位置是否为null,如果是null直接存入
如果位置不为null,表示有元素,则调用equals方法比较属性值
- 如果equals属性值一样,不存入
- 如果equals属性值不一样,存入数组,形成链表
jdk8以前:新元素存入数组,老元素挂在新元素的下面
jdk8以后:新元素直接挂在老元素下面,
- 这样组成的链表长度超过8,而且数组长度大于等于64时,自动转换为红黑树
如果集合中存储的是自定义对象,必须要重写hashCode和equals方法
HashSet的三个问题
HashSet为什么存和取的顺序不一样
hashSet在遍历取的时候,是从数组的0索引开始遍历的,索引下有链表的话就依次遍历,而存数据是根据数据的hashCode值去存的,不是从0索引开始,链表中的数据,也不是按照顺序去存的。
HashSet为什么没有索引
数据结构不够纯粹,是由数组、链表、红黑树组成,不太好定义那个是0索引、那个是1索引,所以就取消了索引。
有人会说,可以使用数组下有索引,但是数组下会存在链表或者红黑树,这么多数据的话公用一个索引不合适。
HashSet是利用什么机制保证数据去重的。
利用HashCode方法(得到哈希值)和equals方法(比较对象内部属性的值)
LinkedHashSet(有序、不重复、无索引)
这里的有序是指保证存储和取出的元素顺序一致。
原理:底层数据结构依然是哈希表,只是每个元素又额外多了一个双链表的机制记录存储的顺序。
如果以后要数据去重,我们使用哪个?
默认使用HashSet,如果要求去重且存取有序,才使用LikedHashSet
TreeSet(可排序、不重复、无索引)
- 可排序:按照元素的默认规则(由小到大)排序
- 对于数值类型:Integer,Double,默认按照从小到大的顺序进行排序
- 对于字符、字符串类型,按照字符在ASCII码表中的数字升序进行排序,字符串类型,就是从第一个字母开始比较,相同则继续往下比较,如果比较的字母不同,按照ASCII码表中的数字升序进行排序,不在比较后续的字母,所以字符串排序与字符串长度无关。
- TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都比较好
TreeSet的两种比较方式
使用原则:默认使用第一种,如果第一种不能满足当前需求,就是用第二种
方式一
默认排序/自然排序:JavaBean类实现Comparable接口指定比较规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103package com.zhuixun.pojo;
import java.util.Objects;
/**
* @Author: zhuixun
* @Date: 2023/1/28 12:55
* @Version 1.0
*/
public class Student implements Comparable<Student>{
private String name;
private Integer age;
public Student() {
}
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
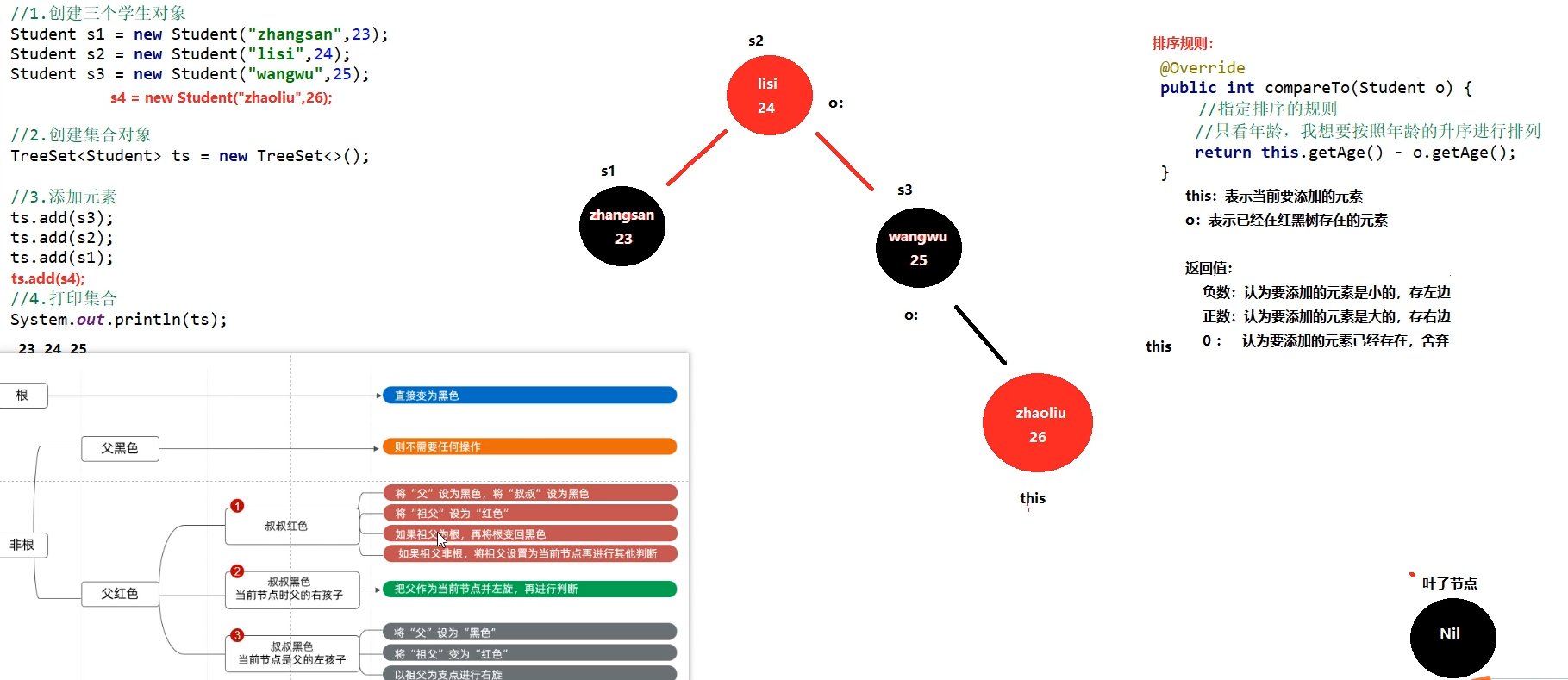
public int compareTo(Student o) {
//指定排序规则 this:当前要添加的元素 o:已经存在红黑树中的元素
//返回值:负数:表示当前添加的元素是小的,要存左边
//正数:表示当前添加的元素是大的,要存右边
// 0 : 表示当前添加的元素已存在,则舍弃不存
int i = this.getAge()- o.getAge();
return i;
}
}
package com.zhuixun.demo;
import com.zhuixun.pojo.Student;
import java.util.TreeSet;
/**
* @Author: zhuixun
* @Date: 2023/1/28 12:50
* @Version 1.0
*/
public class TreeSetDemo {
/**
* 需求:创建TreeSet集合,并添加三个学生对象
* 学生对象属性:
* 姓名、年龄
* 要求按照学生的年龄进行排序
* 同年龄按照姓名字母排序(暂不考虑中文)
* 同姓名、同年龄认为是同一个人
*
* 方式1: 默认排序/自然排序:JavaBean类实现Comparable接口指定比较规则
*
*
*/
public static void main(String[] args) {
//1.创建三个学生对象
Student s1 = new Student("zhangsan",23);
Student s2 = new Student("lisi",24);
Student s3 = new Student("wangwu",25);
//2.创建集合对象
TreeSet<Student> ts = new TreeSet<>();
//3.添加元素
ts.add(s3);
ts.add(s2);
ts.add(s1);
//4.打印集合
System.out.println(ts);
}
}存入红黑树过程
方式二
比较器排序:创建TreeSet对象的时候,传递比较器Comparrator指定规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public void treeSetDemo2(){
/**
* 需求:请自行选择比较器排序和自然排序两种方式
* 要求:存入四个字符串:"c","ab","df","qwer"
* 按照长度排序,如果一样长则按照首字母排序
* 采用第二种排序,比较器排序
*/
//1.创建集合 o1:表示当前添加的元素,o2表示已经在红黑树存在的元素
//返回值:负数:表示当前添加的元素是小的,要存左边
//正数:表示当前添加的元素是大的,要存右边
// 0 : 表示当前添加的元素已存在,则舍弃不存
TreeSet<String> ts = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
//按照长度排序
int i = o1.length()-o2.length();
//如果长度一样按照首字母排序
i=i==0?o1.compareTo(o2):i;
return i;
}
});
ts.add("c");
ts.add("ab");
ts.add("df");
ts.add("qwer");
//打印集合
System.out.println(ts);
}
