Map接口
Map集合
1. map是一个双列集合,每次添加元素都是按对添加,分为键和值。
2. 键是唯一的,不可以重复,值可以重复。键和值之间是一一对应的关系。
3. 一个键和值我们称之为"键值对"或者是"键值对对象",在java中叫做"Entry对象"
Map中的体系结构
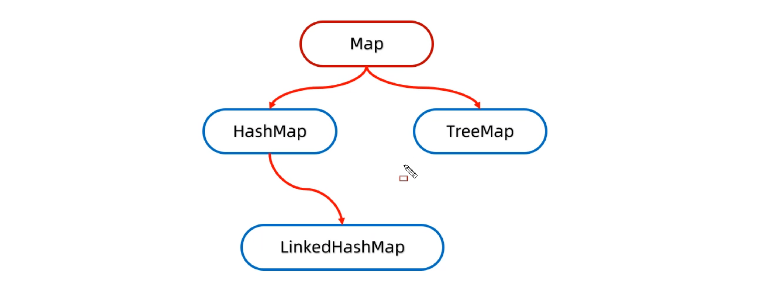
Map中常见API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的。
| 方法名称 | 说明 |
|---|---|
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
Map的遍历方式
键找值
- 先获取所有键的单列集合
- 遍历单列集合
- 通过遍历出来的键使用get方法找到对应的值
1 | |
依次获取键值对
- 依次获取键值对对象(Entry对象)
- 通过getKey()获取键,通过getValue()获取值
1 | |
Lambda表达式
底层就是利用第二种方式(依次获取键值对)遍历
1 | |
HashMap
1.HashMap是Map里面的一个实现类。
2.没有额外需要学习的特有方法,直接使用Map里面的方法就可以了
3.特点都是有键决定的:存取无序、键不重复、无索引
4.HashMap跟HashSet底层原理是一模一样的,都是哈希表结构
底层原理
- 创建一个长度为16,默认加载因子为0.75
- 利用put方法添加数据时,会先创建一个Entry对象,
利用键计算哈希值,跟值无关,判断哈希值在数组中的索引位置- 如果该位置为null则直接存入
- 如果该位置不为null,
会调用equals方法比较键的属性值,如果键里面的属性值一样,就会覆盖原有的Entry对象- 如果键的属性值不一样,就会添加新的Entry对象
- 在Jdk8以前,新元素会添加在数组中,原先的会挂在下面,形成链表
- jdk8以后就直接添加在原先元素的下面,形成链表
jdk8以后,为了提高查询速度,当链表长度超过8并且数组长度大于等于64,自动转为红黑树
小结
- HashMap底层是哈希表结构的
- 依赖hashCode方法和equals方法保证键的唯一
- 如果键存储的是自定义对象,需要重写hashCode和equals方法
- 如果值存储自定义对象,不需要重写hashCode和equals方法
练习
需求:创建一个HashMap集合,键是学生对象,值是籍贯
存储三个键值对元素并遍历
要求:同姓名,同年龄认为是同一个学生
核心点:HashMap的键位置如果存储的是自定义对象,需要重写hashCode和equals方法
1 | |
需求:
某班级80名学生,现在需要组成秋游活动,班长提供四个景点依次A、B、C、D,每个学生只能选择一个景点,请统计出最终哪个景点想去的人数最多。
1 | |
源码解析
快捷键CTRL+F12
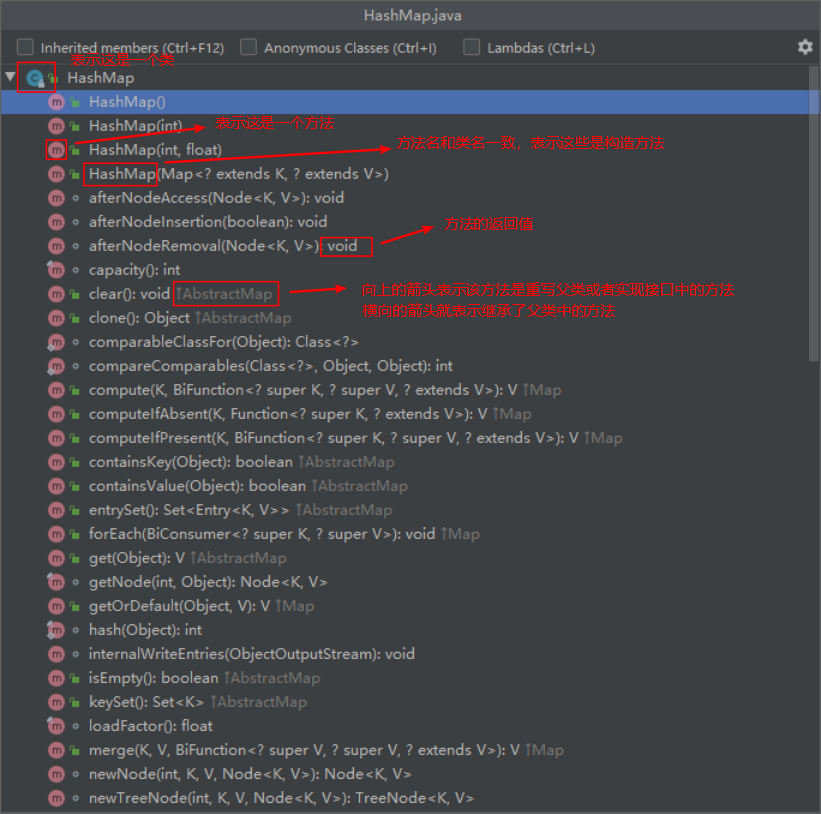
HashMap源码注释解析
1 | |
LinkedHashMap
- 由键决定:有序、不重复、无索引。
- 这里的有序指的是保证存储和取出的元素顺序一致
- 原理:底层数据结构依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录
TreeMap
- TreeMap跟TreeSet底层原理一样,都是红黑树结构的,增删改查性能较好
- 由键决定特性:不重复、无索引、可排序
- 可排序:
对键进行排序 注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则
代码书写两种排序规则
- 实现Comparable接口,指定比较规则
- 创建集合时传递Comparator比较器对象,指定比较规则
1 | |
需求:
字符串:”aababcabcdabcde”
统计字符串中每一个字符出现的吃书,并按照格式输出
a(5)b(4)c(3)d(2)e(1)
新的统计思想:
利用Map集合进行统计如果题目中没有要求对结果进行排序:默认使用HashMap要求对结果进行排序,请使用TreeMap
1 | |
源码解析
1 | |
思考问题
TreeMap添加元素的时候,键是否需要重写hashCode和equals方法?
回答:此时是不需要重写的。因为hashCode和equals与hashmap中的键有关,并且在TreeMap源码中也没看到重写hashCode和equals方法
HashMap是哈希表结构的,JDK8开始由数组,链表,红黑树组成的。既然有红黑树,HashMap的键是否需要实现Compareable接口或者传递比较器对象呢?
回答:不需要的。因为在HashMap的底层,默认是利用哈希值的大小关系来创建红黑树的
TreeMap和HashMap谁的效率更高?
回答:如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时TreeMap的效率要更高。但是这种情况出现的几率非常的少。一般而言,还是HashMap的效率要更高。
你觉得在Map集合中,java会提供一个如果键重复了,不会覆盖的put方法呢?
此时putIfAbsent本身不重要。
传递一个思想:
代码中的逻辑都有两面性,如果我们只知道了其中的A面,而且代码中还发现了有变量可以控制两面性的发生。
那么该逻辑一定会有B面。
1 | |
- 三种双列集合,以后如何选择?
HashMap LinkedHashMap TreeMap
1 | |
可变参数
可变参数本质上就是一个数组
作用:在形参中接收多个数据
格式:数据类型…参数名称
举例:int…a
注意事项:
- 形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
Collections
1. java.util.Collections:是集合工具类
2. 作用:Collections不是集合,而是集合的工具类
Collections常用的API
| 方法名称 | 说明 |
|---|---|
| public static | 批量添加元素 |
| public static void shuffle(List<?> list) | 打乱List集合元素的顺序 |
| public static | 排序 |
| public static | 根据指定规则排序 |
| public static | 以二分查找法查找元素 |
| public static | 拷贝集合中的元素 |
| public static | 使用指定元素填充集合 |
| public static | 根据默认的自然排序获取最大/小值 |
| public static | 交换集合中指定位置的元素 |
综合练习
班级有N个学生
需求:70%的概率随机到男生,30%的概率到女生
思路:Random随机抽取某一个数,这个是随机点。概率问题就是一个随机面(可以把1,1,1,1,1,1,1,0,0,0放入一个数组,再去Random随机,1就去再去随机男生的list,0就去随机女生的list)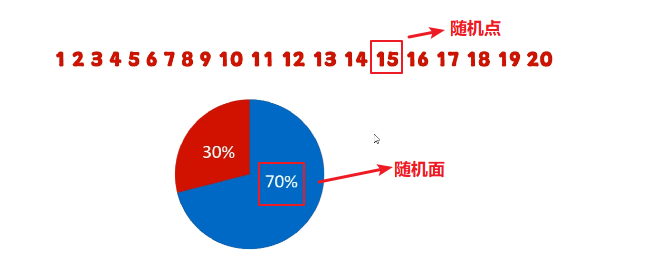
1 | |
班级有N个学生
要求:
被点到的学生不会再被点到,但是如果班级中所有的学生都点完了,
需要重新开启第二轮点名。
1 | |